Explore large image datasets with Panoptic
- Track: Open Research
- Room: AW1.126
- Day: Saturday
- Start: 14:15
- End: 14:40
- Video only: aw1126
- Chat: Join the conversation!
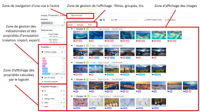
Panoptic is a tool to explore locally and easily big images datasets: https://github.com/CERES-Sorbonne/Panoptic Images abound on the web and digital social networks. Their proliferation is one of the characteristics of digital culture. In particular, they are widely mobilized in contemporary controversies, with the aim of revealing and debating important social issues. Far beyond natively digital images, whether moving or still, images are first and foremost an object of study in their own in many disciplines (art history, film studies...), just as they can be a way of accessing a research field (photographs of animal and plant species, pages from digitized books...). A key challenge for the human and social sciences is to equip themselves with tools for exploring, sorting and annotating image corpora.
While a number of tools already exist for working with such corpora (XnView, Tropy, voxel51, Aikon, Arkindex, for example), a key issue to be resolved is the multiplication in the number of images we work with: how can we efficiently explore, sort and annotate a corpus of several tens of thousands of images? How can we provide researchers with a tool that facilitates such work?
Indeed, working with a large number of images means first of all having a synoptic view of them, in order to understand them as a whole, but also being able to manipulate them directly in the presentation interface (for both exploration and analysis).
Secondly, working with a large number of images also imposes time constraints on analysis, which can be resolved by using similar-image clustering tools (computer vision tools), to group together images that have formal similarities (reduces exploration time), but also by using batch annotation functionalities (reduces analysis time).
Finally, working with images is rarely just about working with images, but also with textual data associated with the images (texts of tweets, photographer's name, shooting date, etc.). Another challenge, then, is to adopt a plurisemiotic approach to the content of the corpus being worked on, in order to avoid having to move back and forth between different work spaces.
Created at CERES, by developers, researchers and designers, Panoptic is an open source tool for visualizing, exploring and annotating large images corpora. In particular, the tool integrates algorithms for grouping images by similarity (by using ml model CLIP), to help users with sorting and exploration. The tool also offers various filtering, search and annotation options, enabling the creation, analysis and export of sub-corpora.
Our talk will present the tool we have developed, and how its various functions are designed to meet the methodological needs of research using tools for working with large volumes of images.
Speakers
| Félix Alié | |
| David Godicke | |
| Edouard Bouté |