Beyond TinyML: Balance inference accuracy and latency on MCUs
- Track: AI Plumbers
- Room: UD2.120 (Chavanne)
- Day: Saturday
- Start (UTC+1): 11:50
- End (UTC+1): 12:10
- Chat: Join the conversation!
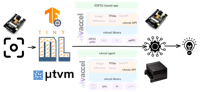
Can an ESP32-based MCU run (tiny)ML models accurately and efficiently? This talk showcases how a tiny microcontroller can transparently leverage neighboring nodes to run inference on full, unquantized torchvision models in less than 100ms! We build on vAccel, an open abstraction layer that allows interoperable hardware acceleration and enable devices like the ESP32 to transparently offload ML inference and signal-processing tasks to nearby edge or cloud nodes. Through a lightweight agent and a unified API, vAccel bridges heterogeneous devices, enabling seamless offload without modifying application logic.
This session presents our IoT port of vAccel (client & lightweight agent) and demonstrates a real deployment where an ESP32 delegates inference to a GPU-backed k8s node, reducing latency by 3 orders of magnitude while preserving Kubernetes-native control and observability. Attendees will see how open acceleration can unify the Cloud–Edge–IoT stack through standard interfaces and reusable runtimes.
Speakers
| Charalampos Mainas | |
| Anastassios Nanos | |
| Anastasia Mallikopoulou |